前の関連記事:linuxBean14.04(157)Jupyter Notebookの内容をBloggerに貼りつけたときのCSS
プログラムやモジュールを国際化する手順
23.1. gettext — 多言語対応に関する国際化サービス — Python 3.5.3 ドキュメントに書いてあるこの手順に沿って国際化を行います。
- プログラムやモジュールで翻訳対象とする文字列に特殊なマークをつけて準備します
- マークづけをしたファイルに一連のツールを走らせ、生のメッセージカタログを生成します
- 特定の言語へのメッセージカタログの翻訳を作成します
- メッセージ文字列を適切に変換するために
gettextモジュールを使います
23.1.3. プログラムやモジュールを国際化する
ステップ1はpyファイルを直接編集します。
ステップ2から3はPoeditでやってしまいます。
国際化 (I18N, I-nternationalizatio-N) とは、プログラムを複数の言語に対応させる操作を指します。地域化 (L10N, L-ocalizatio-N) とは、すでに国際化されているプログラムを特定地域の言語や文化的な事情に対応させることを指します。I18NとL10Nの違いを知りたいと思っていたので、ちょうど疑問が解けました。
23.1.3. プログラムやモジュールを国際化する
モジュールで翻訳対象とする文字列に特殊なマークをつけて準備する
まずステップ1です。
特殊なマークとはデフォルトでは_()です。
self.lst_output.append(idl + _("はIDL名ではありません。"))
こんな感じに置換したい文字列を単に_("文字列")とするだけです。拡張子でPythonと認識するので拡張子はpyにしとかないといけません。
よく考えたら、日本語にするのは日本語環境のときだけでそれ以外は英語にした方がよいので、ソースファイルは英語にするべきですね。
ということで、まずpyファイルの日本語文字列を英語文字列にしました。
つまり以下は英語を日本語に置換するための設定です。
Poeditのインストール
Synapticパッケージマネージャでpoeditで検索すると1.5.4が出てきますのでこれをインストール指定します。
このときgettextも一緒にインストールされます。
Poeditはこのgettextのxgettextを使って上記の残りのステップを行います。
豆ボタン→プログラミング→Poedit、で起動できます。
メニューの一部が日本語化されています。
Poeditのパーサの設定を見る
Poeditでの設定はどういうふうにxgettextに反映されるのか確認しておきます。
編集→設定。

パーサタブでPythonを選択して編集ボタンをクリックします。
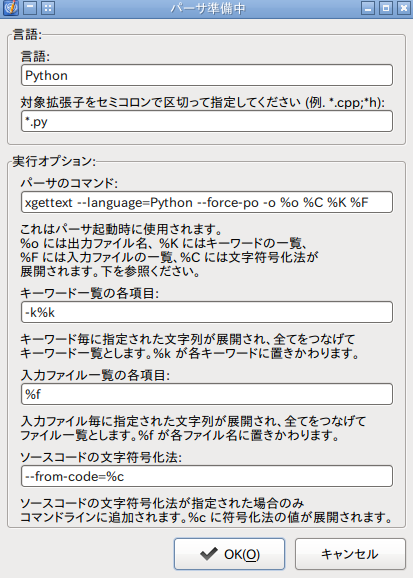
%で始まっている変数はPoeditからxgettextに渡されるものです。
xgettextのオプションの解説はTerminalでxgettext --helpとすると日本語ででてきます。
--force-poは空ファイルでも出力する、ということです。
--from-code=は入力ファイルのエンコーディングを指定します。
「文字符号化法」とは「エンコーディング」のことでした、、、
キーワードというのは23.1.3.4. 翻訳処理の遅延解決の例で使うようなものだと思います。
メッセージカタログであるpoファイルをPoeditで作成する
ステップ2をします。
Poeditでファイル→New Catalog。
Translation propertiesタブの設定

プロジェクトの名前は国際化するファイル名にしました。
すべてを入力しなくても動作はするようです。
入出力ファイルのエンコーディングはUTF-8を選択しました。
複数形は、日本語の場合はGNU gettext utilities: Plural formsに書いてある通り「nplurals=1; plural=0;」にします。
Pythonではgettext.ngettext()とかGNUTranslations.ngettext()を使うときに反映されるようです。
日本語でこれを使う機会は単位変換ですかね。
一匹とか一頭とか一羽とか、日本語は数ではなく、数える対象によって単位が変化しますのでその対応を考えないといけません。
Sources pathsタブの設定
一番簡単そうに思ったこの設定が一番四苦八苦しました。

新しいアイテムボタンをクリックしてソースになるpyファイルへの相対パスを指定します。
ベースのパス.は出力するpoファイルのパスを示します。
この相対パスの指定はpoファイルの出力先に依存します。
Poeditはpoファイルを保存すると同じ場所にmoファイルを出力します。
Pythonのgettextモジュールはこのmoファイルを使って地域化します。
Pythonのgettextモジュールがmoファイルを探す場所は固定しています。
なので、poファイルもmoファイルがあるべき場所に出力することにします。
それでmoファイルのあるべき場所はgettext.find(domain, localedir=None, languages=None, all=False)が検索するパスになります。
解説を読んでもよく理解できなかったので、gettext.pyをデバッガにかけて調べました。
domainは拡張子を除いたmoファイル名になります。
localedirは指定しなければ、gettext.pyのあるフォルダ下のshare/localフォルダになりました。
languagesは指定しなければ環境変数のLANGUAGE、LC_ALL、LC_MESSAGES、LANGから検索されます。
linuxBean14.04ではLANGに ja_JP.UTF-8が入っていました。
それを元にja_JP.UTF-8、ja_JP、ja.UTF-8、jaを順番にlanguagesに入れてmoファイルを検索していました。
具体的にgettext.find(unoinsp)とすると以下のパスを探しました。
share/locale/ja_JP.UTF-8/LC_MESSAGES/unoinsp.mo
share/locale/ja_JP/LC_MESSAGES/unoinsp.mo
share/locale/ja.UTF-8/LC_MESSAGES/unoinsp.mo
share/locale/ja/LC_MESSAGES/unoinsp.mo
shareフォルダのパスは実行しているgettext.pyと同じです。
太字部分はlocaledirの指定に依存します。
なので相対パスの指定はlocaledirの設定に依存します。
以上の結果localedir=./localeとすることにしましたが、localedirは絶対パスで指定が必要のようですのであとで考えることにします。(相対パスでもよいと書いてあるページもありますが私の環境ではうまくいきませんでした。)
localedirはソースpyファイルでの設定に使います。
mkdir -p locale/ja/LC_MESSAGES
ソースのpyがあるフォルダでこのコマンドを実行してpoファイルの出力先フォルダを作成しました。

../../../
パスはこれを指定しました。
Sources keywordsタブの設定

Sources keywordsタブではキーワードの設定を行います。
今回はデフォルトの_しか使っていないのでこれはそのままにしてOKボタンをクリックしました。
poファイルの保存先を聞かれるので、先ほど作成したlocale/ja/LC_MESSAGESフォルダにunoinsp.poという名前で保存しました。
(2017.9.23追記。ひとつのpoファイルで先ほど設定したSources pathsにあるpyファイルすべての単語を抜き出してくるのでpoファイル名はデフォルトのままdefaultの方がよいかもしれません。)

poファイルを保存するとソースのpyファイルが読み込まれて_()で囲った文字列がピックアップされますのでOK。

これでunoinsp.poが作成されてPoeditで読み込まれました。
スペルチェッカーの辞書が見つからないと言われますが、そのようなものはないのでDon't show againをクリックします。
翻訳を作成する

pyファイルから抽出された文字列を選択して、それぞれに対応する訳をTraslationの枠に入力していきます。

保存するとpoファイルと同じ場所にmoファイルが出力されています。
これでステップ3が完了してPoeditのお仕事は終了です。
モジュールを地域化する
23.1.3.1. モジュールを地域化するの通り、gettext.translation(domain, localedir=None, languages=None, class_=None, fallback=False, codeset=None)をモジュールの最初で読み込みます、、、
と、思ったら23.1.3.1. モジュールを地域化するの例は戻り値がバイト文字列であるGNUTranslations.lgettext()を使っているのでモジュールが動きませんでした。
ようやくそれに気がついて、代わりにUnicodeでエンコードされた文字列を返すGNUTranslations.gettext()を使ってちゃんと動くようになりました。
import gettext
import os
lodir = os.path.join(os.path.abspath(os.path.dirname(__file__)),"locale") # このスクリプトと同じファルダにあるlocaleフォルダの絶対パスを取得。
t = gettext.translation("unoinsp",lodir,fallback=True) # Translations インスタンスを取得。
_ = t.gettext # _にt.gettext関数を代入。
このコードを国際化するpyファイルの最初に入れました。poファイルを作成するときに考えた通りdomainをunoinsp、localedirは./localeの絶対パスを取得しています。
これで日本語訳が出力されました。
日本語以外の環境でテストする
最初、期待に反して日本語以外の環境ではNo translation file found for domainとエラーがでました。
これだと「国際化」ではなくて「日本語化」しただけになってしまいます。
gettext.translation()でfallback=Trueを設定していなかったのが原因でした。
上記のコードではすでに修正してあります。
LANG=AAAA
英語環境のテストにはTerminalでこのコマンドを打って国際化したPythonスクリプトを実行しました。
fallback=Trueを設定していると翻訳せずにそのまま英語の文字列が出力されました。
これでモジュールの国際化が完了しました。
ソースのpyファイルの編集がどの程度許されるのか知りたいところです。
poファイルには文字列のある行番号が表示されていますが、gettextのコードを挿入した時点ですでに行番号がずれてしまっているので、その程度の編集は許容範囲であるようです。
よく考えたら関数で置換しているのでソースのpyファイルを編集しても問題はなさそうですね。
Windowsへの対応
Windowsでも使う可能性のあるモジュールなのでWindowsでの環境変数を調べてみました、、、全然ダメそうです。
Windowsでは環境変数から言語を知る方法はないようです。
Python: gettext doesn't load translations on Windows - Stack Overflow
ここにパーフェクトと思われる回答がありました。
if sys.platform.startswith('win'):
import locale
if os.getenv('LANG') is None:
lang, enc = locale.getdefaultlocale()
os.environ['LANG'] = lang
Windowsの場合はLANGがあるかどうか調べてなければ環境変数LANGにlocale.getdefaultlocale()で取得した値を代入しています。C:\Program Files (x86)\LibreOffice 5\program>python
Python 3.3.5 (default, Dec 20 2016, 00:04:55) [MSC v.1800 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import locale
>>> locale.getdefaultlocale()
('ja_JP', 'cp932')
Windows10で調べたところja_JPが代入できています。import gettext
import os
import sys
if sys.platform.startswith('win'): # Windowsの場合。
import locale
if os.getenv('LANG') is None: # 環境変数LANGがない場合
lang, enc = locale.getdefaultlocale() # これで日本語の場合('ja_JP', 'cp932')が返る。
os.environ['LANG'] = lang # LANGにja_JPを代入。
lodir = os.path.join(os.path.abspath(os.path.dirname(__file__)),"locale") # このスクリプトと同じファルダにあるlocaleフォルダの絶対パスを取得。
t = gettext.translation("unoinsp",lodir,fallback=True) # Translations インスタンスを取得。
_ = t.gettext # _にt.gettext関数を代入。
Windows10でコマンドプロンプトで確認するとちゃんと日本語が返ってきました。日本語以外の場合の動作確認はWindows10でlocale.getdefaultlocale()の戻り値を変える方法がわからなかったので確認できていません。
参考にしたサイト
gettext - Wikipedia
国際化ツール。Pythonにはこの仕組みを利用できる同名のモジュールがあります。
GNU gettext utilities
gettextのマニュアル。
23.1. gettext — 多言語対応に関する国際化サービス — Python 3.5.3 ドキュメント
Pythonのgettextモジュールの解説。「国際化」よりも「多言語化」の方がしっくりくる私。
GNU gettext utilities: Plural forms
各言語の複数形への対応方法。
Python で スクリプトのファイルパス を 取得する基本コード (メモ) - Qiita
実行中のスクリプトのディレクトリの絶対パスの取得方法を参考にしました。
ubuntuで端末を英語化する
環境変数LANGに存在しない言語名を入力すると英語化されました。
Python: gettext doesn't load translations on Windows - Stack Overflow
Windowsで環境変数LANGを得る方法。
Ubuntu Manpage: pygettext - Python equivalent of xgettext(1)
xgettextがPythonにも対応したことによりpygettext.pyは非推奨になりました。
Python で スクリプトのファイルパス を 取得する基本コード (メモ) - Qiita
実行中のスクリプトのディレクトリの絶対パスの取得方法を参考にしました。
ubuntuで端末を英語化する
環境変数LANGに存在しない言語名を入力すると英語化されました。
Python: gettext doesn't load translations on Windows - Stack Overflow
Windowsで環境変数LANGを得る方法。
Ubuntu Manpage: pygettext - Python equivalent of xgettext(1)
xgettextがPythonにも対応したことによりpygettext.pyは非推奨になりました。
0 件のコメント:
コメントを投稿